



En nuestro día a día como agencia SEO, solemos encontrar graves problemas en las páginas webs que analizamos, ya sea auditando a nuestros clientes, revisando a la competencia o simplemente curioseando sites por internet.
En este artículo, hemos tratado de recopilar ocho de estos errores técnicos tan graves como comunes que, habitualmente, son consecuencia de no contar con un perfil especializado en SEO en las diferentes fases de un proyecto digital.
Contenidos
- 1 1. Lanzar una web sin ser rastreable o indexable
- 2 2. Olvidar elementos clave a la hora de migrar (PDFs, imágenes, etc.)
- 3 3. No contar con un SEO desde el inicio de un proyecto de nueva web
- 4 4. Canibalización de contenidos
- 5 5. Descontrol en el rastreo del sitio web
- 6 6. Bloquear por robots.txt para desindexar
- 7 7. Errores de enlazado interno
- 8 8. No establecer una versión de dominio preferido
- 9 Conclusión
1. Lanzar una web sin ser rastreable o indexable
¿Cuántas veces nos hemos encontrado con una página de reciente publicación que está bloqueada al rastreo mediante robots.txt o a la indexación mediante un noindex en todas sus URLs?
O en un escenario opuesto: una versión en desarrollo que está completamente abierta y a la que, de algún modo, Google llega y comienza a rastrear e indexar rápidamente, generando contenido duplicado con el de la web en funcionamiento.
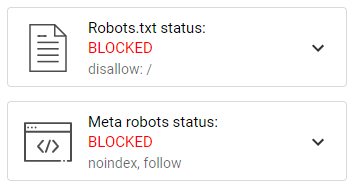
Cualquiera de estas situaciones es, por desgracia, habitual cuando no se tienen presentes los procesos de rastreo e indexación del sitio web por parte de Google.
¿Cuál sería la forma correcta de lanzar un sitio web?
Mientras exista una web en preproducción esta no debe ser rastreable por ningún buscador. Para ello, evitaremos cualquier tipo de enlace hacia esta y la bloquearemos por robots.txt.
Una vez se pase a producción y se publique la nueva web, será el momento de liberarla al rastreo e incluir las redirecciones planteadas en la migración SEO, así como otros elementos necesarios para que Google asimile el cambio. Por ejemplo, que convivan los sitemaps antiguos y nuevos, reemplazar los enlaces internos hacia la versión antigua o notificar el traspaso de dominio en caso de ser necesario.
2. Olvidar elementos clave a la hora de migrar (PDFs, imágenes, etc.)
Las migraciones SEO son un proceso clave a la hora de abordar un cambio de dominio, diseño o estructura web. Todas las URLs actuales deben redirigir hacia su equivalente en la nueva versión web, mientras que aquellas páginas que no tengan un contenido asignable deberán mostrar un código de respuesta 410.
Sin embargo, en ocasiones se producen olvidos de pequeñas partes del sitio web que aparentemente no son importantes pero que pueden suponer una pérdida de tráfico considerable o generar errores en masa. Es el caso de archivos como PDFs, imágenes y otros recursos.
¿Cómo debemos migrar una página web?
Contar con un checklist que contemple todas las tipologías de URLs nos ayudará a evitar olvidos con ningún elemento web de este tipo.
Para ahorrarnos tiempo, es recomendable que estos archivos mantengan su nomenclatura, lo que facilitará el trabajo de matcheo y redirección de las URLs.
3. No contar con un SEO desde el inicio de un proyecto de nueva web
Precisamente los dos errores con los que hemos iniciado este artículo suelen ser consecuencia de la ausencia de un perfil especializado en SEO en el proceso de desarrollo y publicación de una web.
Será fundamental que el SEO esté presente desde el momento 0 en el proyecto, incluso puede ser necesaria su intervención a la hora de establecer presupuestos y condiciones del trabajo a realizar con el cliente.
¿En qué momento del proyecto web debería entrar el especialista SEO?
En este vídeo, te explicamos la importancia de contar con un SEO desde el inicio de cualquier proyecto para evitar problemas en nuestro posicionamiento.
- Acompañamiento SEO- IT: https://www.youtube.com/watch?v=k0ZDUoySddY
Y no solo desde el punto de vista técnico, sino también a la hora de colaborar en la creación de wireframes con el equipo de diseño, así como para realizar un estudio de palabras clave que nos ayude a diseñar una arquitectura web optimizada.
- KWR: https://www.youtube.com/watch?v=idHSRHdQ5-8&t
- Arquitectura: https://www.youtube.com/watch?v=nMdD_R_7g5A&t
En definitiva, si se desean obtener resultados en SEO, así como mantener el posicionamiento logrado hasta la fecha, es vital contar con un especialista en todas las fases del proyecto web.
4. Canibalización de contenidos
Es muy común ver cómo varias URLs de un mismo sitio web comparten intencionalidad de búsqueda y Google no es capaz de escoger la que debe mostrar en sus SERPs ante las consultas de los usuarios.
A esta situación la denominamos canibalización y supone que varias URLs compiten y se perjudican entre sí, evitando que sea una de ellas la que se posicione con mayor claridad.
¿Cuál sería la forma correcta de evitar la canibalización de contenidos?
- Si tenemos la suerte de trabajar desde el inicio, podremos evitar este problema mediante la realización de un keyword research y arquitectura web que tengan en cuenta los diferentes tipos de intencionalidades de búsqueda y nos ayude a concentrar todos nuestros esfuerzos de posicionamiento en un único contenido
- Planificamos un tratamiento mediante canonicals para aquellas páginas de las que no podamos prescindir.
<link rel=»canonical» href=»https://dominio.com/url-canonica/» />
- Además, debemos vigilar la optimización on page, así como el enlazado interno y externo hacia estas páginas para asegurarnos de que no estamos mostrando señales confusas a Google que impliquen esta canibalización.
5. Descontrol en el rastreo del sitio web
Conforme un sitio web crece en número de URLs, cobra vital importancia controlar el rastreo de nuestro sitio web para no malgastar el presupuesto de rastreo que nos asigna Google o crawl budget.
Si no controlamos el rastreo de elementos como filtros, parámetros de ordenación, páginas con contenidos de baja calidad, URLs de feed y otros, podemos agotar el crawl budget y ni siquiera haber rastreado todas las URLs buenas de nuestro sitio que son las que nos traerán negocio.

¿Cómo podemos controlar el rastreo de nuestro sitio web?
Una forma rápida de evitar el rastreo de este tipo de URLs consideradas “malas” será su bloqueo mediante el archivo robots.txt, pero tampoco será positivo contar con un elevado número de URLs del sitio bloqueadas por robots y enlazadas desde diferentes secciones del sitio web.
Así pues, debemos evitar que Google siga estos enlaces mediante el uso del etiquetado nofollow o, preferentemente, la ofuscación de enlaces para no desperdiciar link juice. También controlaremos posibles enlaces ocultos en el código, así como que estas URLs de baja calidad SEO no se incluyan en el sitemap.xml.
6. Bloquear por robots.txt para desindexar
Otro error bastante común fruto de la falta de conocimientos SEO sería el incorrecto tratamiento de las URLs para su desindexación.
Muchas veces -aunque por fortuna cada vez menos- se opta por usar noindex y bloquear por robots.txt una URL dando por hecho que esto hará que no se indexe una página.
Ante esta situación, Google intentará acceder pero no podrá leer su contenido ni la etiqueta noindex. Probablemente la URL pierda el posicionamiento adquirido como consecuencia de este bloqueo, pero seguirá en el índice de Google si continúa enlazada. Por tanto, no tendríamos cumplido el objetivo de mantener la URL fuera del índice de Google.
¿Cuál sería la manera adecuada de desindexar una URL?
- Incluir la directiva noindex a través de una meta etiqueta robots en el HTML o de la cabecera de respuesta HTTP de la página.
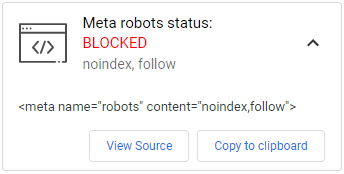
- Mantener la página abierta al rastreo de forma indefinida, para que Google pueda interpretar esta recomendación cada vez que visite la URL y no indexe la página.

- Evitar su enlazado completamente o, en caso de ser necesario por usabilidad, ofuscar los enlaces hacia la página a desindexar.
- Eliminar esta URL de los archivos sitemaps existentes.
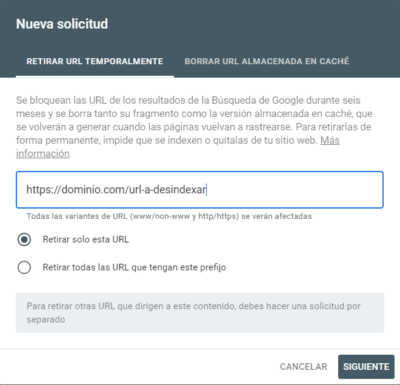
- Solicitar la retirada temporal vía Google Search Console.
7. Errores de enlazado interno
Son muchas las situaciones que pueden derivar en cambios en todas o buena parte de las URLs de nuestro sitio web:
- Migración de dominio.
- Cambios en la arquitectura web y la estructura de sus URLs.
- Añadir o eliminar directorios por idiomas.
- Instalar un certificado de seguridad SSL.
- Etc.
Aunque realicemos las redirecciones oportunas, debemos vigilar todos los enlaces internos y externos que hemos incluido en nuestra web, puesto que es muy probable que se hayan generado enlaces hacia redirecciones y errores 404 de forma masiva.
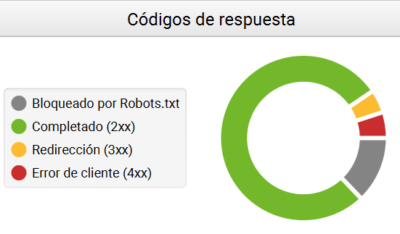
Los enlaces hacia redirecciones acabarán llevando al destino final a los robots de Google y al usuario, pero supondrán un consumo extra de los recursos del primero (crawl budget), así como un incremento en los tiempos de carga para el segundo.
¿Cómo podemos extraer y solucionar los errores de enlazado interno?
- Realizar un rastreo con la herramienta Screaming Frog o cualquier otro crawler de todo el sitio web, simulando el comportamiento de Googlebot a la hora de rastrear enlaces.
- Seleccionaremos la opción “Exportación en bloque” → “Interna y Externa” y exportamos en Excel cada una de las opciones que nos ofrece la herramienta, salvo la de “Enlaces internos completado 2XX” que corresponderá a los enlaces correctos.
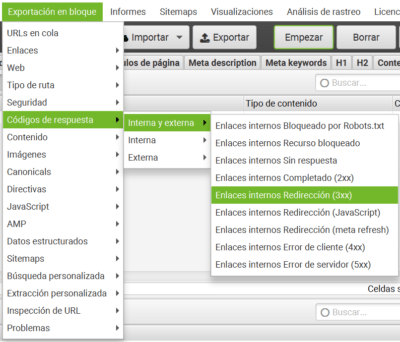
- Una vez exportados los documentos, los unificamos en uno solo y comenzamos con la limpieza de los enlaces.
- Para ubicar los enlaces, nos fijamos en la columna “Fuente”, donde se muestra el origen del enlace. Debemos sustituir la URL de destino por la correcta en cada caso.
8. No establecer una versión de dominio preferido
Pese a tratarse de un elemento básico del SEO, la ausencia de unificación de versiones del dominio es algo más habitual de lo que puede parecer. Son muchas las auditorías en las que detectamos que un sitio web tiene activas diferentes versiones que corresponden a las combinaciones de HTTP-HTTPS y WWW o sin WWW, así como versiones con “/” al final de las URLs.
La combinación de todas estas versiones puede llegar a multiplicar por 8 el número de URLs del sitio, generando un problema de contenido duplicado y de rastreo importante.
¿Cómo debemos proceder para establecer una versión principal de dominio?
Para tratar este problema de contenido duplicado, como consecuencia de la convivencia de diferentes versiones, debemos escoger una como preferida y redireccionar las restantes directamente hacia esta, evitando cadenas de redirecciones.
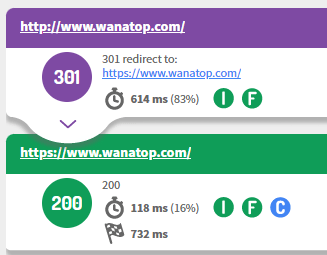
Conclusión
Todos estos errores SEO y muchos otros pueden evitarse contando con un perfil especializado en la materia, ya sea internamente o contratando los servicios de un consultor o una agencia especializada.
En Wanatop le damos el cariño que se merece a cada proyecto y cuidamos todos los detalles de una estrategia SEO para que la evolución y los resultados no se vean entorpecidos por problemas técnicos. Además, es importante monitorizar los proyectos con el paso del tiempo ya que muchos de estos problemas pueden surgir en cualquier momento como consecuencia de otros cambios que aparentemente no están relacionados.
Publicaciones relacionadas:




 David Legarre, Especialista SEO y Analítica Web.
David Legarre, Especialista SEO y Analítica Web.